
 This is what bad data is like…
This is what bad data is like…
Data Quality
How valuable is the Ford Pinto brand? How about a patent for a cat scuba suit? Like other intangible assets, the value of data is rooted in its quality. Nonprofits have an even greater motivation to maintain the integrity of their information, because their organizational success is dependent on effectively communicating via membership data. One of the data quality management tools we deploy at DSK Solutions includes SQL Server 2012 Data Quality Services. DQS is especially valuable because it offers an efficient, semi-automated means for associations to create a data quality foundation to build their enterprise analytics. By identifying data attributes and functional dependencies, DQS can effectively correct bad entries (cleanse) and eliminate duplicate records (match).
The Benefits of Data Quality Services
First, DQS has the powerful ability to automatically discover knowledge about your data. Even with only a sample of the larger data set, DQS can identify inconsistent, incomplete, and invalid data. For example, using Term-Based Relations (TBRs), DQS can identify strings that are inconsistent with the rest of the entries in that column. So, if ninety-nine of your entries use “123 Oak St” as the street address and one uses “124 Oak St,” DQS will correct the odd entry to be consistent. Additionally, developers can build domain rules that define the correct format or value. For example, if a user email does not follow the pattern “[email protected]”, DQS can either mark the entry as invalid for later review or automatically update with the missing characters.
Next, DQS can check for consistencies throughout the record. Using third party reference tools or user-defined rules, associations can validate that data is logical. For example, if an entry lists a member city as “Chicago” and member state as “DC,” DQS can identify the inconsistency and either mark it as invalid or correct it to “IL.” Another valuable feature is that users can develop matching rules to determine duplicate entries. For example, if two records are 95% similar (again, based on user-defined rules), DQS can eliminate duplicate rows and consolidate the data into one unique entry.
 Two types of data profiling
Two types of data profiling
Finally, DQS has an effective user-interface for controlling the discovery and cleansing process. A DQS project steps through mapping the fields to rule domains, creating results that rate data on completeness and accuracy, and managing the project results.
Unfortunately, DQS is not a magic bullet. There are some challenges to implementing DQS for large databases. For example, the implementation of DQS for an AMS/CRM involves many important steps. First, analysts, like DSK Solutions, consolidate problem data into a single table or view (DQS transformations work on one table, not entire databases). Next, associations cleanse and match the data using a combination of DQS SSIS transformation and manual data verification. Finally, data experts reintegrate the groomed data back into the original table structure (including considerations for timing, normalizing, and other SQL scripting).
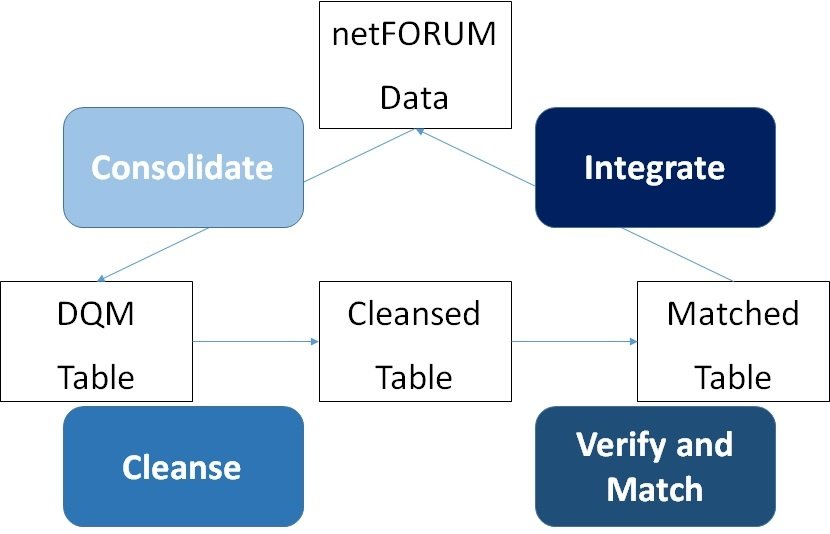 DQS Implementation for netFORUM
DQS Implementation for netFORUM
To conclude, it is important to note the DQS is knowledge-driven, meaning that it will take data-oriented managers to develop a strategy for a final asset. As the non-profit world embraces data, DQS will play a pivotal role in creating the level of quality necessary to build an effective business intelligence infrastructure.


